Why can't we get 100% of the CPU peak performance?
- ridgerun

- Aug 12, 2020
- 4 min read
Updated: Apr 29, 2024


Theoretically, the Formula 1 below is used for computing the peak performance of a CPU (based on the architecture of Figure 1 below):
Formula 1:
Where


Figure 1 - Modern CPU resource distribution
However, the peak performance can also depend on the environment of the application. Most of them may not run using all the cores to not affect other applications. In this case, we can adapt the Formula 1 mentioned above according to the context.
Some experiments
As a part of our duties, we have checked the peak performance of a node which belongs to a supercomputer in Trieste, Italy. To summarize the characteristics of this node:
CPU: Dual Intel® Xeon® Processor E5-2697 v2
RAM: 32 GB
Storage: Lustre on Infiniband EDR
OS: Minimum CentOs 7 - kernel 3.10
Having a look at the processor, from Intel Ark we can get:
According to the APP Metrics document provided by Intel, 259.2 GFLOP/s is the peak performance per CPU. Since the node is dual CPU capable, the peak performance is multiplied by 2:
Now, it’s time to check that number experimentally. From the wide collection of Benchmarks, we are going by High-Performance Linpack (HPL) with Intel MKL which exploits the computation power of the machine.

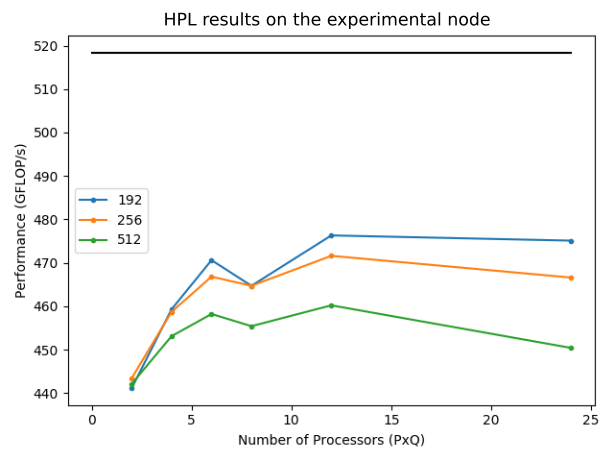
Figure 2 - Benchmark results by using a configuration of the block size (nb = {192, 256, 512}), and several configurations for the number of cores (PxQ). The best mark: 476.41 GFLOP/s (91.9%)
According to Figure 2, the best mark achieved was 91.9% of the peak performance of the node experimentally.
Which are the reasons we could not go further?
Let’s land on the question of the day. There are some reasons we cannot go further than 91.9% for technical reasons. The configuration of both processors is illustrated as follows:


Figure 3 - Typical Dual CPU configuration in Intel architectures
The first thing to notice is that both CPUs are connected by Quick Path Interconnect (QPI). When computation synchronization occurs, both CPUs send messages through the QPI bus, adding some overhead to the process. In fact, QPI communication is one of the reasons to not get 100% of the peak performance. Nevertheless, on single CPU configuration, we are not able to go further.
To examine which other factors can affect the performance, let’s have a look at the internal of a CPU:

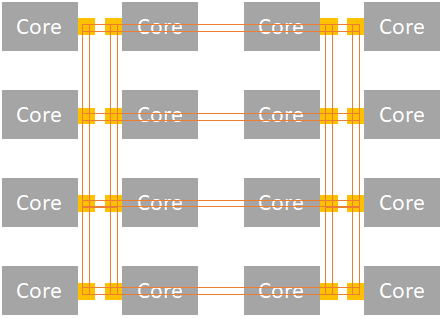
Figure 4 - Intel Skylake core mesh
Cores also need to synchronize depending on the workload. This can add some latency when sending messages from two cores in opposite sites (left-top to right-bottom, for example). This can count as an administrative penalty which is really unavoidable but optimizable by using thread-affinity in some cases. Additionally, the OS can add extra overhead when coordinating processes between cores.
Now, we are about to arrive at one of the topics which encourage this blog entry: intrinsics penalty. Yes, using intrinsics has some penalty on the overall performance on the CPU. It is possible to get a good scaling in performance when using intrinsics. However, the scaling will not be perfect most of the time.
From the Optimizing Performance with Intel Advanced Vector Extensions, the scaling from SSE 4.2 (4 32-bit Floating-Point) to AVX (8 32-bit Floating-Point), the scaling is about 1.8x times. This suggests that there is some loss when scaling with intrinsics. There are some enhancements with AVX2, where the number of operations was doubled but the scaling is not linear yet.
One of the reasons why using vectorization doesn’t scale linearly is the vector slow-down. Using the vector execution units usually slows the CPU down because of power consumption. According to the Specification Update for Second Generation Intel Xeon Scalable Processors, for the SKU 6256 : Intel® Xeon® Gold 6256 Processor (as a reference, see Figure 5), we have the following behaviour in the maximum frequencies and using all the cores (12 for Intel® Xeon® Gold 6256 Processor):
No AVX: 4.3 GHz
AVX 2: 3.8 GHz
AVX 512: 3.3 GHz


Figure 5 - Maximum frequency achievable when enabling vectorization (SKU: 6256-Intel® Xeon® Gold 6256 Processor)
Using as a baseline that the scaling for 8 simultaneous operands, the non-AVX version would have a “frequency” of 34.4 GHz. With AVX 2 at 3.8 GHz, we are likely to have 30.4 GHz, which means 88% of the linear scaling. Hence, if we implement AVX 2, the maximum speed-up achievable is 7.04 times instead of 8.
A similar situation happens with AVX 512. Going for 16 operands with linear scaling, the frequency will be ideally 68.8 GHz. With AVX 512 at 3.3 GHz, the frequency is 52.8 GHz (76.7%). It means that the maximum scaling from 1 operand at the time to 16 operands with AVX 512 would be 12.3 times out of 16.
If we add the efficiency (n) to our first formula:
Where we integrated the number of CPUs per node and the efficiency. For AVX2 in our experimental node. However, the efficiency may depend on the processor and also by the running frequency. For the experimental node, the efficiency may be at least 0.919 in the best case.
Would you like to team up with RidgeRun for your next project?
RidgeRun has an expertise on GPU acceleration, AI , FPGA's, Digital Signal Processing and camera drivers for Linux. If you are interested in our services, do not hesitate to email at support@ridgerun.com.
Contact Us:
Visit our Main Website for the RidgeRun online store and pricing information of the RidgeRun products and Professional Services. Please email support@ridgerun.com for technical questions. Contact details for sponsoring the RidgeRun GStreamer projects are available at Sponsor Projects page.
Intel® Xeon® are trademarks of Intel Corporation.
SkyLake is an Intel microarchitecture.